The PEPT Library’s Documentation#
A Python library that unifies Positron Emission Particle Tracking (PEPT) research, including tracking, simulation, data analysis and visualisation tools.
Positron Emission Particle Tracking#
PEPT is a technique developed at the University of Birmingham which allows the non-invasive, three-dimensional tracking of one or more ‘tracer’ particles through particulate, fluid or multiphase systems. The technique allows particle or fluid motion to be tracked with sub-millimetre accuracy and sub-millisecond temporal resolution and, due to its use of highly-penetrating 511keV gamma rays, can be used to probe the internal dynamics of even large, dense, optically opaque systems - making it ideal for industrial as well as scientific applications.
PEPT is performed by radioactively labelling a particle with a positron- emitting radioisotope such as fluorine-18 (18F) or gallium-68 (68Ga), and using the back-to-back gamma rays produced by electron-positron annihilation events in and around the tracer to triangulate its spatial position. Each detected gamma ray represents a line of response (LoR).
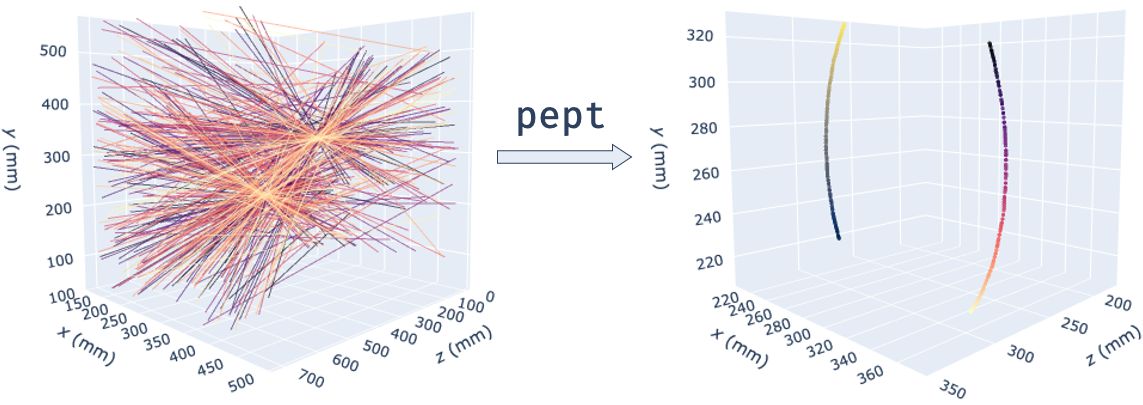
Transforming gamma rays, or lines of response (left) into individual tracer trajectories (right) using the pept library. Depicted is experimental data of two tracers rotating at 42 RPM, imaged using the University of Birmingham Positron Imaging Centre’s parallel screens PEPT camera.
Tutorials and Documentation#
A very fast-paced introduction to Python is available here (Google Colab tutorial link); it is aimed at engineers whose background might be a few lines written MATLAB, as well as moderate C/C++ programmers.
A beginner-friendly tutorial for using the pept package is available here (Google Colab link).
The links above point to Google Colaboratory, a Jupyter notebook-hosting website that lets you combine text with Python code, executing it on Google servers. Pretty neat, isn’t it?
Performance#
Significant effort has been put into making the algorithms in this package as fast as possible. Most computationally intensive code has been implemented in Cython, C or C++ and allows policy-based parallel execution, either on shared-memory machines using joblib / ThreadPoolExecutor, or on distributed computing clusters using mpi4py.futures.MPIPoolExecutor.
Copyright#
Copyright (C) 2021 the pept developers. Until now, this library was built directly or indirectly through the brain-time of:
Andrei Leonard Nicusan (University of Birmingham)
Dr. Kit Windows-Yule (University of Birmingham)
Dr. Sam Manger (University of Birmingham)
Matthew Herald (University of Birmingham)
Chris Jones (University of Birmingham)
Mark Al-Shemmeri (University of Birmingham)
Prof. David Parker (University of Birmingham)
Dr. Antoine Renaud (University of Edinburgh)
Dr. Cody Wiggins (Virginia Commonwealth University)
Dawid Michał Hampel
Dr. Tom Leadbeater
Thank you.
Indices and tables#
Documentation
Pages